

















Bioinformaticians know that good data analysis is always founded on good data; even the best chef struggles to make a gourmet meal from rotten food. In the biotech and pharma industries, reliable data is a critical part of meaningful breakthroughs for patients.
New repositories and public consortia like GEO, GTEx, Blueprint and more have concentrated unprecedented amounts of experimental data, free for anyone to use. But the abundance of free data brings its own problems. Along with new buzzwords like “big data” and “data lake”, phrases like “data silo” and “did I just process all that data for nothing” have become more familiar.
Luckily, improvements in life are possible for everyone, data scientists included. QIAGEN offers two knowledge bases that are ready for data scientists to explore, created with discovery in mind. We’ve already done the hard work of cleaning, processing and standardizing the data for you.
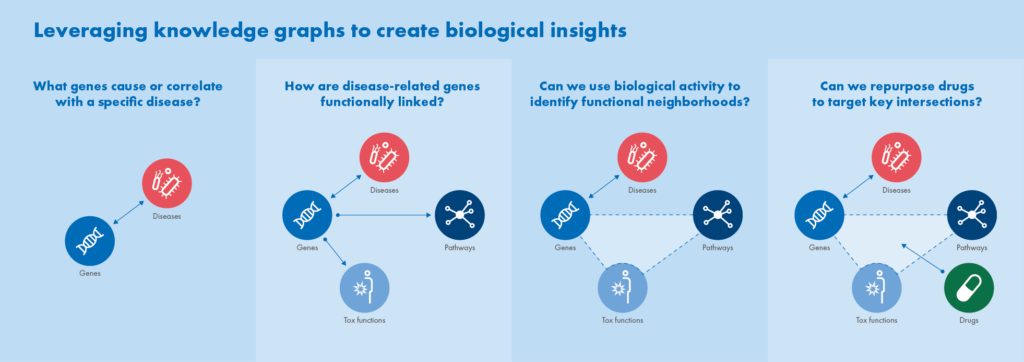
While they both concentrate on relationships data, there are still some differences to consider. Let’s see what makes these knowledge bases tick.
Model training requires high quality biological data – that’s why we extracted the knowledge base powering QIAGEN Ingenuity Pathway Analysis, cited in over 50,000 publications. Biomedical KB-HD hosts over 24 million manually curated biomedical relationships, unified under a comprehensive ontology. Thanks to the efforts of our curators, KB-HD has the quality causal relationships that you need to confidently support your research and power model training.
Informatics and data science teams can use their time more efficiently with KB-HD. It has already been deployed for mechanism of action studies, knowledge graph explorations, hypothesis generation, drug portal projects and drug discovery models.
Artificial intelligence (AI) has already been used to streamline drug discovery timelines, and we’re applying it towards clinical phases too. Our newest knowledge base combines our biomedical relationships with deep variant collections, which can be used for recruitment, triaging and CDx development.
Biomedical KB-AI is a collection of biomedical relationships generated with natural language processing (NLP). This enables faster data processing, which has allowed us to create the largest collection of biomedical relationships data, composed of over 640 million relationships connecting genes, molecules, diseases and more. KB-AI also sources knowledge from patents, grants and pre-publication arXiv sources, which makes it ideal for strategic analyses that rely on late-breaking research, including patent landscape explorations.
Schedule a free interactive demo with our Application and Data Science team. They’ll be happy to show you how these resources can support your specific applications.












