

ATCC Cell Line Land
Manually curated cell line ‘omics data from the most popular cell lines in ATCC's collection
ATCC Cell Line Land is a continually growing database of cell line ‘omics data from both common and novel human and mouse cell lines and primary tissues and cells from ATCC. It empowers you to precisely plan and design your preclinical experiments by speeding up cell line characterization with unique, high-quality cell line ‘omics data from a trusted source.

Cell line ‘omics data from a credible source you can trust
Cell lines form the cornerstone of preclinical studies that help researchers like you understand the underlying mechanisms of normal and disease biology. Yet, inaccuracies in public datasets and cell line contamination adversely affect your research, hamper your insights and lead you to false hypotheses.
To make it easier for you to access and use cell line ‘omics data for cell line characterization, we’ve partnered with ATCC to establish ATCC Cell Line Land. This is a unique database with transcriptomic (RNA-seq) and genomic (whole exome sequencing) datasets from the most highly utilized human and mouse cell lines and primary tissues and cells in ATCC’s collection. This database of ATCC cell line ‘omics data helps you quickly, easily and cost-effectively advance your drug development.
‘Omics data derived from ISO-compliant cell lines
ATCC offers credible, authenticated and characterized cell lines and primary sources for reproducible research results. The advantage of working with ‘omics data from ATCC Cell Line Land is that the data is derived from cell lines cultured in ISO-compliant conditions. This means the data is reliable and comes from pure, uncontaminated samples. The transcriptome or whole genome is then sequenced from the cell line in replicate, and the resulting ‘omics data is processed and curated using our stringent and rigorous methods for ‘omics data curation, structuring and integration.

Build efficiency into your preclinical research
ATCC Cell Line Land delivers high-quality, expert-curated ‘omics data from ATCC cell lines to save you valuable time and resources while empowering your drug discovery research.
Powerful ‘omics data visualizations in ATCC Cell Line Land help you quickly find relevant cell line ‘omics data for your gene of interest, understand expression levels of a single gene or multiple genes across different cell lines and reveal gene signatures. You can generate hypotheses by mining cell line datasets for tissues, diseases and treatments of interest, then combine and slice up the datasets to reveal patterns that correspond to clinical parameters, and find known compounds and treatments that affect your targets.
Relevant data for unique and valuable discoveries
ATCC Cell Line Land is continually growing, with ‘omics data on 1000 new samples each year. These datasets, along with their metadata, are processed and curated using our uniform data processing and metadata curation standards, using controlled vocabularies and extensive manual curation. What you get is high-quality cell line ‘omics data, complete with consistent data labels and vocabulary- and formatting-controlled metadata. We capture metadata on multiple aspects of each cell line, including standard culture conditions, extraction protocols, sample preparation and NGS library preparation. This consistency in metadata curation of ATCC cell line ‘omics data means you’ll be able to quickly identify unique traits across cell lines with speed and accuracy to home in on the data most relevant to your research.
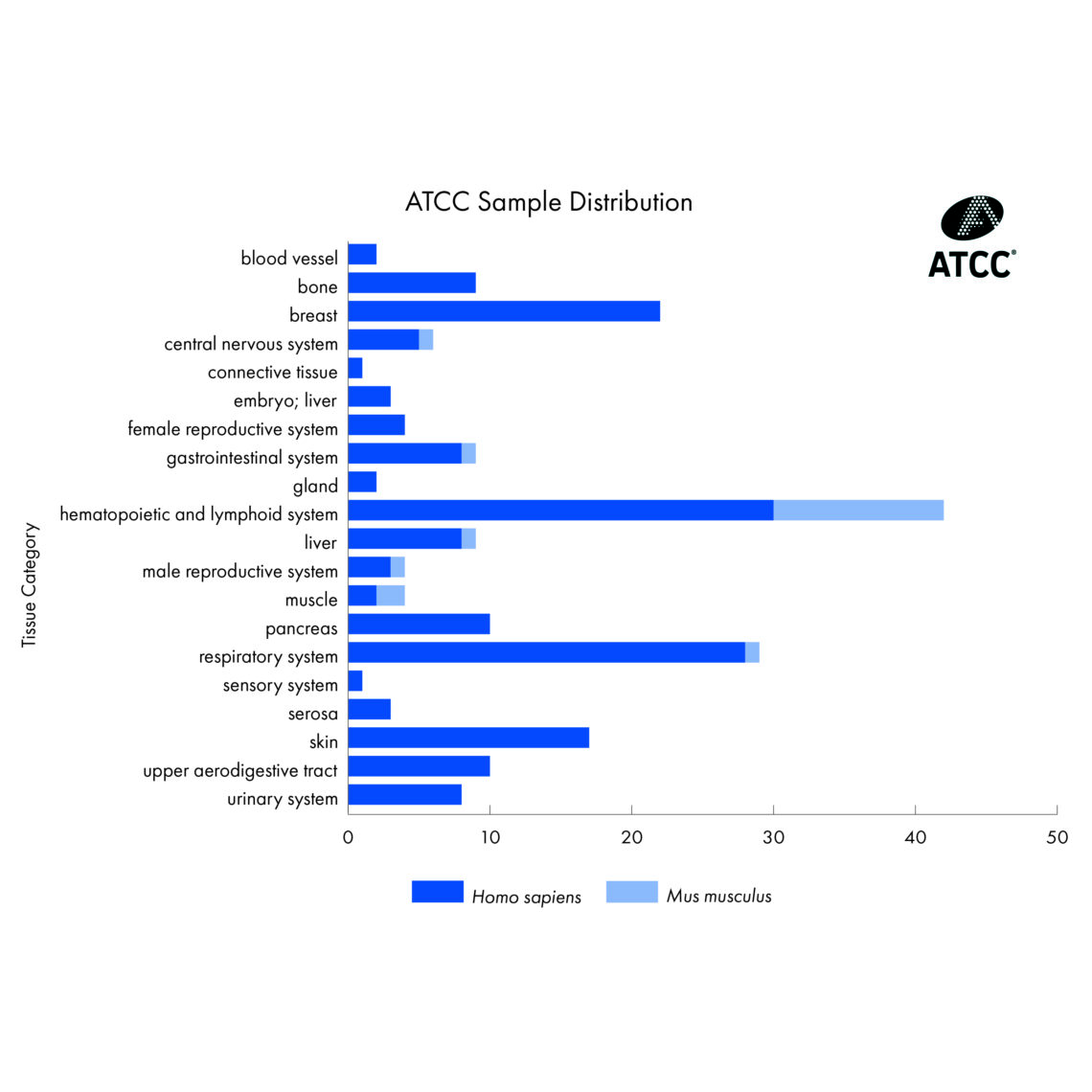
Cell line samples across tissue categories in ATCC Cell Line Land.
“Every dataset we produce can be traced to a physical lot of cells in our bio repository. Since there are no questions around reproducibility and traceability of those materials, you end up with maximum data provenance.”
– Jonathan Jacobs, PhD, Senior Director of Bioinformatics, ATCC

Features
- Quality-controlled data from ATCC human and mouse cell lines
- Careful metadata curation with controlled vocabulary
- Reprocessed and normalized expression and whole genome sequencing data
- Metadata include standard culture conditions, extraction protocols, sample preparation and NGS library preparation
- Over 1000 new datasets added each year with quarterly releases
- Data grows based on what you, as a researcher, need most: Our team takes your requests to prioritize the cell lines you want added to our ATCC Cell Line Land collection, as well as the type of experimental data you want curated
Flexible access for complex multi-omics queries
If you’re a data scientist focused on ‘omics analysis, you’re probably consumed by maintaining your data lake and structuring the specific data you need. You may be frustrated by the gaps and inconsistencies in dataset metadata that cause your queries to return misleading results that could negatively impact your research.
With API access to QIAGEN OmicSoft data, you no longer must find, ingest and maintain databases that contain aggregations of public ‘omics data riddled with inconsistencies. Instead, you’ll be empowered to get right to the data analysis with queries of small or huge data slices from our unified ‘omics database.

Our rigorous metadata curation approach combined with API access to structured and integrated ‘omics data allows you to perform large and complex cross-database, multi-omics queries. We also offer flat file options for ingesting the data into your own database or through our GUI designed for ‘omics visualization.
Related products and resources

QIAGEN OmicSoft Portfolio
Powerful cloud-enabled ‘omics GUI, complete NGS analysis workflows and unparalleled curated content for immediate exploration

QIAGEN Discovery Bioinformatics Services
A reliable and convenient way to extend your in-house resources with expertise and tailored bioinformatics services that ensure high-quality results
